BrainFartLab
Passion projects and ruminations related to IT development.
Project maintained by brainfartlab Hosted on GitHub Pages — Theme by mattgraham
Related
Overlord: my personal BC/DR
As a freelancer you are responsible for your own “IT landscape”, and you can choose to design your own BC/DR (business continuity / disaster recovery) solution however way you prefer. A while ago, my mini-computer had a rocky boot and it dawned on me I had not put enough thought into my BC/DR setup. If my machine were to kick the proverbial bucket, the loss would include:
- a lot of data
- passwords in my keychain
- setups for various programming languages refined over the years
You can now understand the two parts: business continuity means that if a machine goes down, I want to be able to continue work to the best of my ability as fast as possible on a new machine. That means I need to be able to get a new machine up and running fast without having to configure and reinvent the wheel.
The disaster recovery part deals with minimizing your data loss and restoring it. Not all data must be restored in order to continue working on any current tasks, hence the split. Disaster might struck during the day, if you can just focus on work for the rest of the day (= business continuity), you can restore all remaining missing data in the evening, when issues peter down.
In BC/DR, we often talk of the RTO (recovery time objective) and RPO (recovery point objective). The RTO is the time required to resume business critical operations whilst the RPO relates to the amount of data loss expected. In our case we strive to hit a RTO and RPO of < 1 hour.
The RPO is a little odd to express in time units, but you can reason about it using the worst case scenario. If we backup every hour and our machine goes down at say 09:59, we can expect to lose close to an hour worth of data. On the other hand, it might just as well occur at 09:01, in which case we lose close to nothing.
Strategy
Hardware
There’s an underutilised Synology NAS (network attached storage) backup station whirring peacefully in my meter room. It was intended to be used as a backup, but complacency decided otherwise. With some automation we can schedule backups every hour. There are existing cloud solutions, but I wish to keep any sensitive data local. Keeping it local also ensures we are not at the mercy of an internet blackout. This will constitute our disaster recovery.
As for the business continuity on the hardware front, I have a laptop and several mini computers in my possession. I am a huge sucker for the Minisforum machines, you can pack some serious hardware in that small box. I figured most offices will offer me a screen and keyboard anyways in case a role is not fully remote.
Software
On the software front, since Linux is my default OS, Ansible is a good candidate for automating the configuration of my work environment. Since I have plenty of machines, I can easily SSH from one into another and configure it with Ansible. Performing initial configuration on any new machine will be minimal, since Ansible is agentless. However, if things go really awry I want to be able to configure my new machine without the need for another. The more accessible my process resources are the better, using USB sticks, Github, and more.
Ansible Collection
I decided to divide my configuration into manageable modules using Ansible roles and test, test and test again. For the testing we utilise Molecule to provision environments based on virtualization or containerization. I went for Podman in this scenario using the Fedora image. After some thoughts I decided on the following roles:
- base: global configuration such as elementary packages and hardware configuration
- terminal: OhMyZsh, color themes, vim plugins, T-MUX
- credentials: cloning my encrypted password store and GPG keys
- synology: Synology setup for hourly syncing and pulling new data on login
- rust: Rust tools
- python: Python tools
- node: Node tools
- golang: Golang tools
With these in place I can access protected resources, get right into using my terminal and productivity tools, synchronize my backed up data and use my goto programming languages. I decided to host my roles on Ansible Galaxy, building and publishing them using Github Actions:
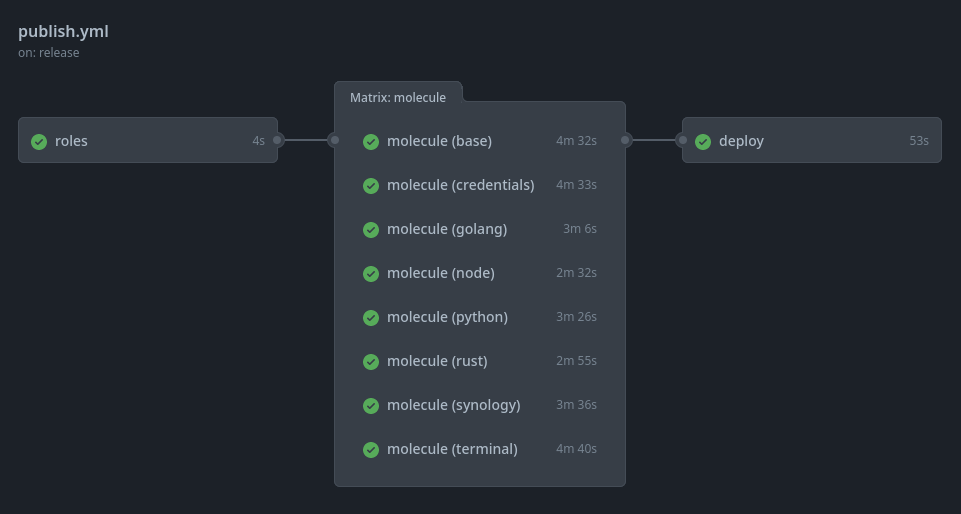 Github Actions workflow for publishing to Ansible Galaxy
Github Actions workflow for publishing to Ansible Galaxy
The workflow can be inspected here. And now they end up published on Ansible Galaxy:
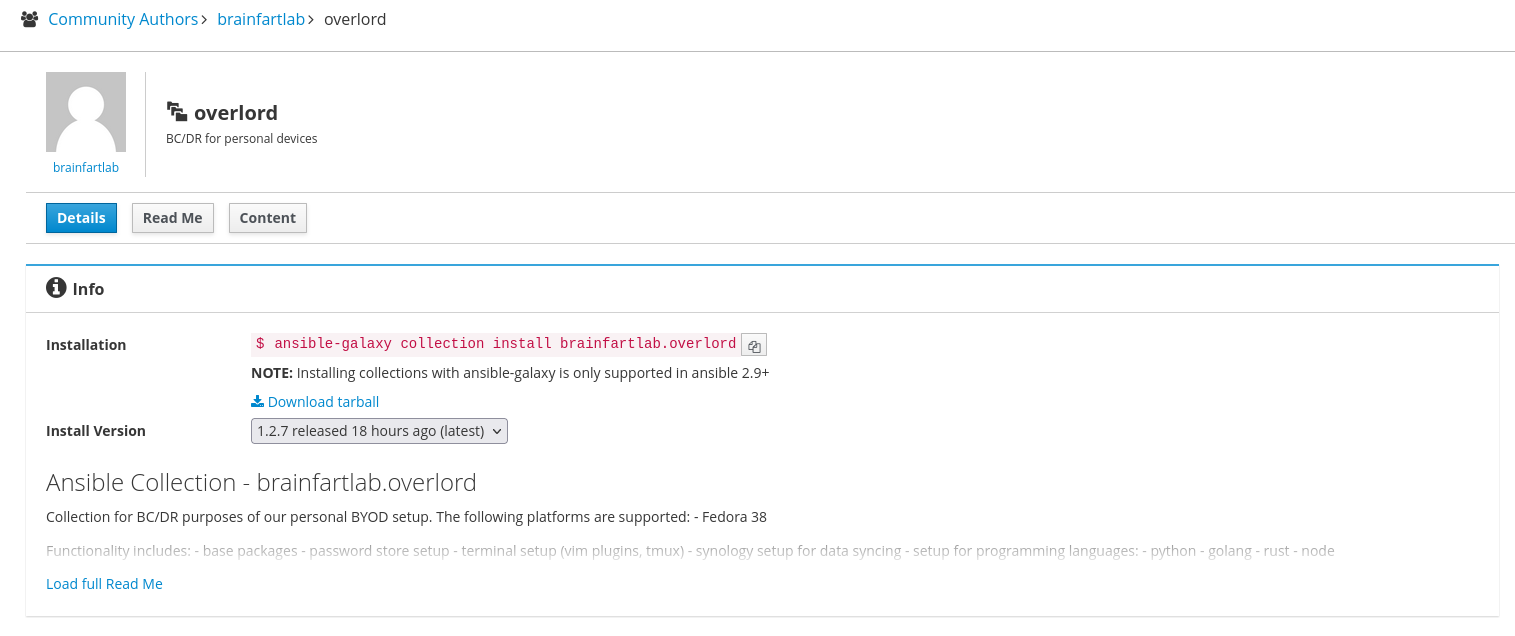 Ansible Galaxy overlord collection
Ansible Galaxy overlord collection
You can browse the code for the collection here. As time progresses, roles can be modified or appended. For example I could add another role to setup AWS by installing the CLI (requiring the python role) and pre-installing CDK (requiring the node role). Or the base role can be modified to include Fedora repositories such as the RPM Fusion repository.
Ansible Playbooks
With the collection in place, the roles can be used in an Ansible playbook. For this we started the byod repository. The new machine will need to be bootstrapped. For us this means:
- Fedora is installed
- Latest updates installed
- SSH allowed from the LAN, optionally setup an SSH key pair
- The LAN IP has been added to the Ansible inventory in case of remote configuration
We possess a protocol document that highlights any manual steps needed during the process, something you will also find in a corporate BC/DR process. There are two playbooks present.
Omaha
This playbook is to be executed at the root user level on the new machine. It will run the base role and create the default users on our Linux OS. Once done, we can execute the user-specific playbook.
Bangalore
This user-specific playbook installs per user the non-global roles, such as the programming roles, the terminal and credentials role.
BC/DR Testing
There are a number of test scenarios possible to evaluate your BC/DR routine. The simplest is a tabletop exercise where you go over your plan without executing any of the steps. This approach serves as a refresher but is also prone to omission of important considerations.
On the other far end is a live test. This is the most work intensive, at least the first time around. You will however learn the most and be able to refine the BC/DR process, making it quicker for future occurrences. You can check whether you missed any vital configuration, more importantly you get to know whether it is any good at all. I recommend performing a live test once a year. The feedback will aid in keeping the process up to date, both code- and documentation-wise. Another advantage of the live test is gauging whether it meets the RTO and RPO objectives you set out to achieve.
Wrap up
With our BC/DR process in place, we now feel secure in our ability to recover from a host of incidents in the future. Mitigating risk is always a balancing act, carefully considering the frequency and impact of threats. For example, a plane could crash into our workplace, but is that worth planning for? You tell me.